
I recently held a talk about OpenID and OAuth 2.0 using the Sitecore Identity Server as an example. In this post I have rewritten my notes and will provide a quick and practical guide to Sitecore Identity Server.
This guide will primarily cover access tokens – what they are and how we get them from Sitecore Identity Server. If you are looking for ways to configure client applications in Sitecore Identity Server, I already covered the topic in the introduction of this blog post.
Also be aware that there is many facets of Identity Management, OAuth 2.0 and OpenID. In this post I will primarily cover the typical use case for web application: Getting access tokens from an Identity Server to use in API calls.
The Sitecore Identity Server
The Sitecore Identity Server (SIS) was introduced in Sitecore 9.1. Built on the IdentityServer4 framework, Sitecore Identity Server exposes OpenID Connect and OAuth 2.0 compliant endpoints. Hence, OpenID and Auth 2.0 are specifications which Sitecore Identity Server implements.
A central role of Sitecore Identity Server is to generate temporary security credentials (tokens) to client application on behalf of user. This will allow client application to access resources (e.g. call the Sitecore APIs). This roles is called STS – being a Secure Token Service.
In a Sitecore setup, the users are typically stored in Sitecores security database (most likely the core database). This can be set using this setting in Sitecore Identity Server configuration:
Sitecore:IdentityServer:SitecoreMembershipOptions:ConnectionString
However, in this post we will simply look at how we can use the Sitecore Identity Server from a practical perspective. A lot of what is described in this post will also apply to other Identity Servers.
How to use a Identity Server
Everything we need to know about the capabilities of an (Sitecore) Identity Server is exposed via a metadata document: [baseurl]/.well-known/openid-configuration.
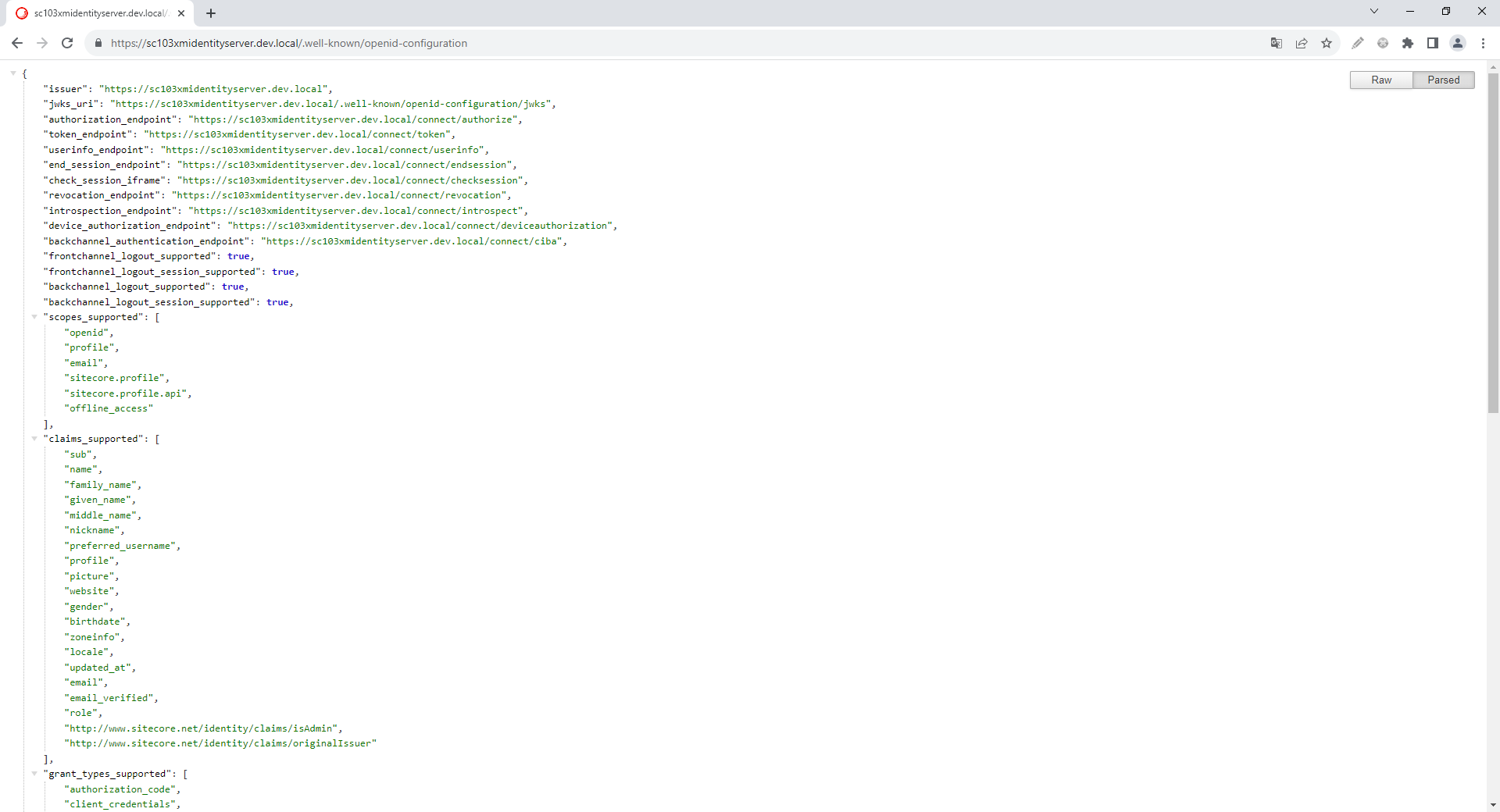
The format of the document is part of the OpenID specification. So if you ever need to authorize a client for e.g. Microsoft Graph API, the Microsoft STS has a similiar document (login.microsoftonline.com/[TENANT ID]/.well-known/openid-configuration).
JWT tokens
In the metadata document we will find the token_endpoint URL. This is the endpoint we normally call to get temporary security credentials in the form of tokens.
We will cover three types of tokens: access tokens, id tokens and refresh tokens. Normally the first two is in the JWT token format. Access tokens are what we typical understand as tokens: We get them and pass them on the APIs we need to call.
But before we start to look to much into the types of tokens, let us look at the JWT format itself: The JWT format consists for a header (JSON), a payload (JSON) and a signature.
Each part of the token is encoded using base64 encoding and joined with a “.”. So, an actual token just looks like three random string of characters separated by “.” – but the token can easily be decoded using e.g. https://jwt.io – or we can simply split the string in three parts, and decode each part. This means that whomever gets the token (e.g. an API) can read the header, the payload and the signature.
The header (decoded) simply contains information about the token:
{
"typ": "JWT"
"alg": "RSA",
}
Here the token is of the type JWT, and the signature is of the type RSA.
The payload is a JSON object containing claims. The claims are the actual core of the token. They describe to whom the token was issue, and – for access tokens – what the holder of the token should be allowed to do.
The metadata document includes a list of all claims that the Identity Server uses. They might not all be present in all types of tokens, and often the access token only contains the claims the API will need to validate whether the holder of the access token is allowed to call the API:
{
"iss": "https://your-identity-server",
"nbf": 1695830911,
"iat": 1695830911,
"exp": 1695834511,
"aud": [
"sitecore.profile.api",
"'https://your-identity-server/resources"
],
"scope": [
"openid",
"sitecore.profile",
"sitecore.profile.api"
],
"client_id": "your-client-id",
"sub": "6bcf5733b7ca432a820c08408572f2d5",
}
The claims may vary from Identity Server to Identity Server. However, the claims above a some of the typical claims used in access tokens.
- The
iss(issuer) claim tells which Identity Server issued the token. - The
nbf(not before) andexp(expire) indicate the timespan in which the token is valid. - The
aud(audience) claim tell to whom the access token is issued. This claim is used a bit different in different implementations. We will return to this. - The
sub(subject) tells which user authorized the client application. - Finally, the list of scopes (
scopeorscp) indicated the permissions the user allowed the client application to obtain. A few scopes have predefined meanings (openid,profile,email, andoffline_access). The rest is implementation specific. We will return to this as well.
Finally, the token contains a signature. The signature is the hash (SHA256) of the base64 encoded header + the base64 encoded payload encrypted using the algorithm specified in the header.
This is often the RSA algorithm which is a encryption mechanism having a public and private key. This means that the Identity Server uses the private key when generating the signature, but we can use the public key to decrypt the signature.
There is a lot of encoding and encryption going on, but what one do is:
rsaEncrypt(hash(base64encode(header) + "." + base64encode(payload)))
To validate a token issued using the RSA algorithm the receiver of the token (e.g. the API) can decrypt the signature using the public key of the Identity Server (explosed via the jwks_uri endpoint) and compare it to the actual hash of the base64 encoded header and payload. If they match, the token is valid. Again in pseudo code:
parts = token.split(".")
header = base64decode(parts[0]);
payload= base64decode(parts[1]);
signature = base64decode(parts[2]);
signedHash = rsaDecrypt(signature)
actualHash = hash(base64encode(header) + "." + base64encode(payload))
return (signedHash == actualHash)
It is important to note that this approach means that the token is not actually validated by the Identity Server (e.g., by sending the token to the Identity Server). Whoever gets the token (e.g an API), can find the iss claim, look up the metadata document, find the jwks_uri endpoint and get the public key of the Identity Server that signed the token.
Knowing the public key of the Identity Server, anyone can validate the token: If the timespan and signature is correct, the token is valid. After this the receiver will typically do some additional check (checking whether the issuer is trusted, the audience is correct, and the token contains the expected scopes). But at no point the Identity Server is needed to actively validate the token. This is referred to as a self-contained token. It is pretty clever, but it also means that the token cannot be invalidated. Once it is issued it will be valid until it expires.
However, the trick here is that one cannot change the token. If we unencode the payload and header – change them – and then encode them, the actualHash would change, but the signature would still contain the old hash. And there is no way we can generate a new signature (containing the new actualHash and being “decryptable” using the public key of the Identity Server) without knowing the private key used by the Identity Server for signing.
Types of tokens
So now that we understand the inner workings of a JWT token, lets look at how they are used: The OAuth2 version of the token_endpoint is used to issue access token and refresh token – often together in a token bundle (a JSON object returned from the endpoint including both tokens).
The access token is issued to a client application on behalf of a user to allow the client application access to some resource (e.g., via a API – the resource owner). As mentioned earlier, the aud claim might indicate the client application or the resource owner. This seems to be dependent on the particular implementation. When a client application needs access to some resource, the client application will include the access token – often in the header of e.g., an API request.
As the access token cannot be revoked (and will be passed on to e.g., APIs), it most likely has a short timespan (typical 5-15 minutes) in which it is valid. Hence it is also possible to issue a refresh token to the client application. The refresh token is not a JWT token and should be kept secret within the client application. This is because the refresh token can be used to request a new access token once the old is expired without having the user login again. When this is done, the Identity Server will actually validate the refresh token. This means that in contrast to the access token, the refresh token can be invalidated (revoked). This happens via the revocation_endpoint. Often when a new access token is issued using a refresh token a new refresh token is also issued, and the old one is automatically invalidated. This is called refresh token rotation.
So, the use case for access tokens (and by extension refresh tokens) are authorization. They are used by client application to access to some resource (often an API).
However, in OpenID – which is an extension to the OAuth 2.0 specification, the token_endpoint can also issue a id token as part of the token bundle. The token is a user profile in the form of a JWT token. It cannot be used to access anything, but simply tells who called the token_endpoint and can be used for authentication.
Obtaining a token bundle
Now that we understand what a token is and how they are used, lets look at how we can obtain a token bundle. Obviously, we need to call the token_endpoint, but we need to provide some proof (called credentials) of who we are and also what we want the token_endpoint to return.
We will request a list of scopes when we call the token endpoint (the scopes we would like included in our access token). The list might include a some implementation specific scopes (like sitecore.profile and sitecore.profile.api). However, a few scopes have special meaning:
- The
offlinescope indicates that we want to get a refresh token. - The
openidscope indicates that we want to get an id token containing thesubclaim. - The
profilescope indicates that to get the user profile (name). - The
emailscope indicatess that we want to get the user’s email.
For ways of providing credentials, we can choose from a list of what is referred to as grant types – the supported types are listed in metadata of the Sitecore Identity Server:
{
"authorization_code",
"client_credentials",
"refresh_token",
"implicit",
"password",
"urn:ietf:params:oauth:grant-type:device_code",
"urn:openid:params:grant-type:ciba"
}
Each grant type except different credentials: We already touched upon the refresh_token grant type – we can send a valid refresh token as credentials to the token_endpoint and get a new token bundle.
The password grant type is also pretty easy to understand: We will send the username and password to the Identity Server as credentials together with a client id and client secret.
The latter is used to validate the client application requesting access on behalf of the user and is configured in Sitecore Identity Server in a Client node:
<Clients>
<MyClient>
<ClientId>my-client-id</ClientId>
<ClientName>MyClient</ClientName>
<AccessTokenType>0</AccessTokenType>
<AllowOfflineAccess>true</AllowOfflineAccess>
<AlwaysIncludeUserClaimsInIdToken>false</AlwaysIncludeUserClaimsInIdToken>
<AccessTokenLifetimeInSeconds>3600</AccessTokenLifetimeInSeconds>
<IdentityTokenLifetimeInSeconds>3600</IdentityTokenLifetimeInSeconds>
<AllowAccessTokensViaBrowser>true</AllowAccessTokensViaBrowser>
<RequireConsent>false</RequireConsent>
<RequireClientSecret>true</RequireClientSecret>
<AllowedGrantTypes>
<AllowedGrantType1>password</AllowedGrantType1>
</AllowedGrantTypes>
<AllowedCorsOrigins>
</AllowedCorsOrigins>
<AllowedScopes>
<AllowedScope1>openid</AllowedScope1>
<AllowedScope2>sitecore.profile</AllowedScope2>
<AllowedScope3>sitecore.profile.api</AllowedScope3>
</AllowedScopes>
<ClientSecrets>
<ClientSecret1>my-client-secret</ClientSecret1>
</ClientSecrets>
<UpdateAccessTokenClaimsOnRefresh>true</UpdateAccessTokenClaimsOnRefresh>
</MyClient>
</Clients>
With this configuration in place, we can request a token with the password grant type (here written in PowerShell):
$Uri = 'https://your-identity-server/connect/token'
$ContentType = 'application/x-www-form-urlencoded'
$Body = @{
grant_type='password'
username='sitecore\admin'
password='b'
scope='openid sitecore.profile sitecore.profile.api'
client_id='my-client-id'
client_secret='my-client-secret'
}
$Response = Invoke-WebRequest -Uri https://your-identity-server/connect/token -Method POST -ContentType $ContentType -Body $Body
$JsonResponse = $jsonObj = ConvertFrom-Json $([String]::new($response.Content))
Write-Host $JsonResponse.access_token
One could imagine that this was the normal way of obtaining access tokens from a client application. However, this would involve the client application collecting the username and password and send them to the Identity Server, which would not be optimal.
So, the normal way is to use the Authorization Code Flow. The basic idea is to redirect the browser to a login page directly on the Identity Server (this is called the authorization_endpoint, but it is an actual webpage).
In the redirect to this webpage we will provide information like the client id, the requested scopes and a redirect URL. The Identity Server will then:
- Find the client (this is done in Sitecore Identity Server by finding the client whos
ClientIdmatches the one provided by the client application). - Validate the redirect URL against the clients whilelisted redirect URLs (set in Sitecore Identity Server using the
RedirectUrisnode in the client configuration). Notice that the client configuration above does only allow thepasswordgrant type and therefore does not have any whitelisted redirect URLs. - Log the user in directly on the Identity Server checking username and password.
- Redirect the user’s browser back with a short-lived authorization code (the maximum lifetime is 10 minutes, but often shorter) – either in a querystring, as part of the URL or as part of a form post (the support types of redirects are listed in the metadata under
response_modes_supported). The form post is the most secure because the authorization code will not be part of the URL, but it is not possible to do a form post in all scenarios.
This authorization code can then be used to call the token_endpoint using the grant type authorization_code. This is more secure because the client application will never know the username and password, but only have access to the short-lived authorization code.
Some details
While we now understand the basic working of an Identity Server, OAuth 2.0 and Open ID, there is a few concepts I would like to mention:
Sitecore Identity Server as a Federation Gateway
First of all, until know we have presumed that the Sitecore Identity Server is looking up the users in the security database and that is also often the case. But it is also possible to federate this task to another Identity Provider (called a subprovider) with Sitecore Identity Server acting as a federation gateway. In this case the Sitecore Identity Server will log the user in using another Identity Provider (e.g., Azure AD), transform the claims from the subprovider to match the one expected by the client application (e.g. Sitecore), and then pass on the transformed claims to the client application. Because of these transformations, the client application might not even know that the authorization request was federated.
This type of arrangement is often used to login on client applications using a list of different Identity Providers (Google, Microsoft, Facebook etc) as I am sure you have seen online.
Proof Key for Code Exchange
When you start venturing into the world of Identity Servers from a web perspective it is also beneficial to know one way we often use to secure the Authorization Code Flow. The flow has three security measures already build in:
- The redirect URL of the client application used during the redirect to the
authorization_endpointneeds to be known (whilelisted) by the Identity Provider. - The authorization code is short-lived.
- A client secret is required when exchanging an autorization code to a token bundle.
But in theory anyone with the authorization code and client secret could exchange the authorization code to a a token bundle by calling the token_endpoint. And the client secret (which does not change from request to request) is really hard to hide on e.g., a mobile or SPA application because it would need to be somewhere in the code, and would also be available if one use a proxy like Charles or Fiddler to inspect the traffic (on a classic server based web-page the request can be made server-to-server).
So if I could get the client secret from a legitimate login (e.g. my own account), and then set up a man-in-the-middle attack obtaining other users authorization codes when they return from the authorization_endpoint I could potentially bypass all three security measures.
To guard against this a mechanism called PKCE is used, making the “client secret” (under another name) change for each request: The client generates a random string (the code_verifier) and hashes it using a one-way hashing algorithm (SHA256) creating a code_challenge. When redirecting to the authorization_endpoint, the hashed value is sent along with the redirect. When the authorization code is issued the code_challenge is stored on the Identity Server. Once the token_endpoint is called the unhashed code_verifier is sent as part of the request instead of a fixed client secret. Before issuing the token bundle, the Identity Server will then hash the code_verifier and check if is matches the expected code_challenge
The trick is to ensure that the client application who started the authorization flow (generated the code_verifier), is also the one getting the resulting token without having to store client secrets on unsecure devices like mobile phones.
Final thoughs
I hope you found this post informative. Identity Servers are complex and support many different scenarios. But often the integrations can be boiled down to a two-step process: Obtaining some type credentials – either from an actual user interaction or from a configuration (in cases when an active user is not involved) and then passing them on to the token_endpoint to obtain an access token and potentially also a refresh token.
When designing and especially debugging integrations with Identity Servers it is beneficially to keep this two-step process in mind and look at which type of credentials we are obtaining, and how we utilize them when calling the token_endpoint.
Also keep in mind that there are often four parties involved in these flows: A user, a client application, an Identity Server, and a resource owner (often an API). Often the user and the client application are “mixed up” conceptually, which makes the flows harder to understand.