
In this blog post I will present a sample integration between the Open AI GPT generative language models and Sitecore XM. This integration will allow content editors to generate content directly from Sitecore using an array of language models including ChatGPT.
The integration, called SitecoreSuggest is available from my GitHub and adds a new Suggest button in the Content Editor’s Review ribbon. This will allow the content editor to automatically generate content using Open AI.
IMPORTANT UPDATE: Be aware a number of completions models mentioned in this post is currently being phased out. This includes my “model of choice” the text-davinci-003 and a number of the older completions models, which will be unavailable from the 4th of January 2023. The new prefered completions model are gpt-3.5-turbo-instruct which cost the 1/10 of the price and has similiar capabilites as text-davinci-003. See the planed deprecations here.
The suggest button
Before we dive into the technical details, let us look at how SitecoreSuggest work from an editor perspective. We will start out by adding a page about ducks:
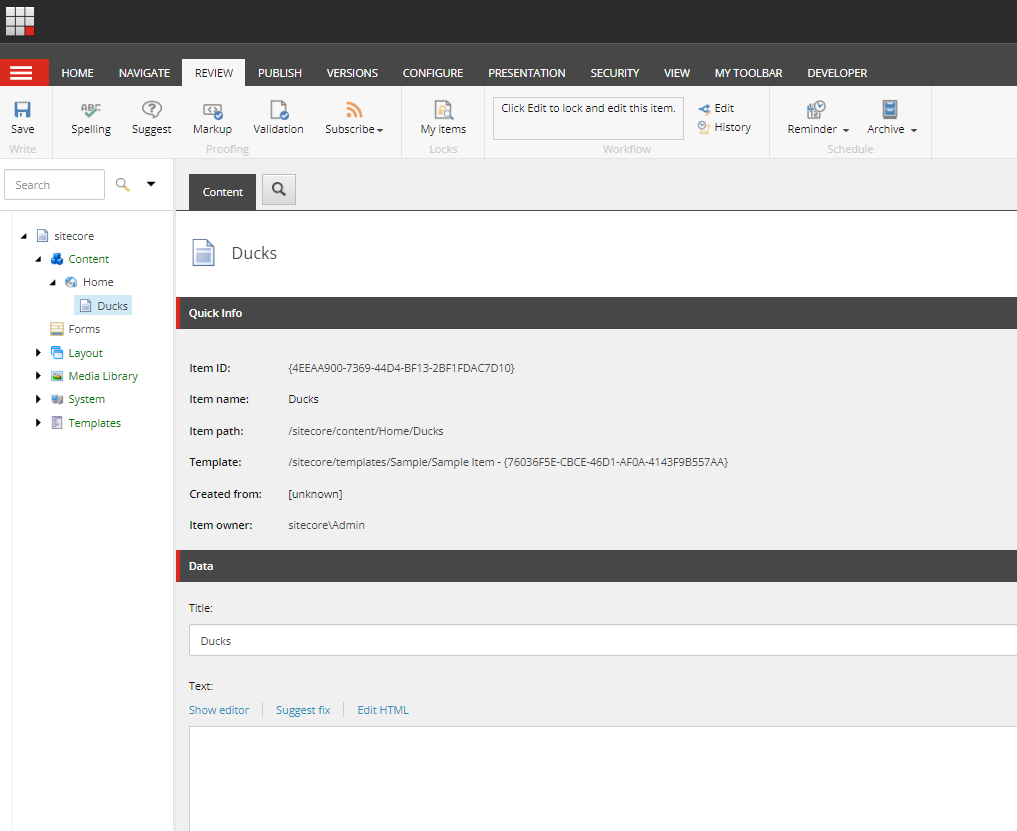
The Title is already filled because the templates standard value uses the $name token in the Title field. The rest of the fields, including the rich text field Text is of cause empty.
But instead of manually entering a text about ducks, a content editor can use SitecoreSuggest by clicking on the Suggest button in the Review ribbon, bring up this dialog:
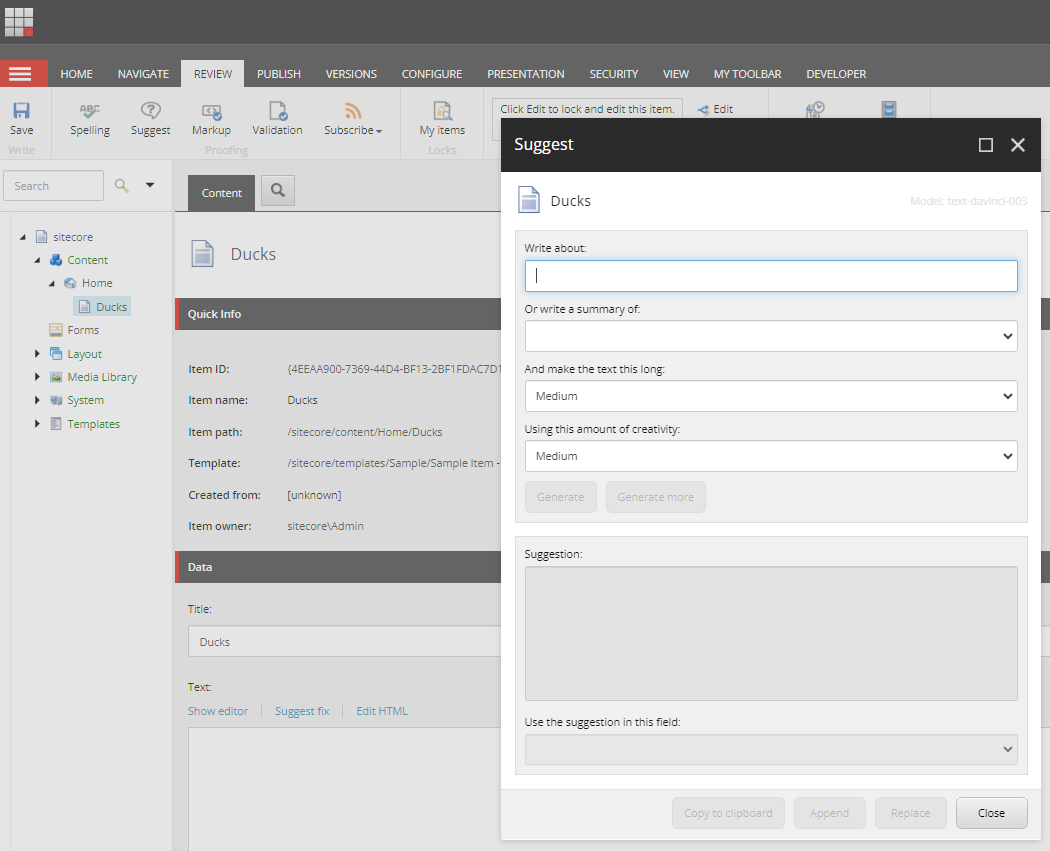
As we already have a title for the item, we will select to generate a text based on the value of the Title field. This is done by using the summary dropdown which has been prefilled with the word “Ducks” and click Generate:
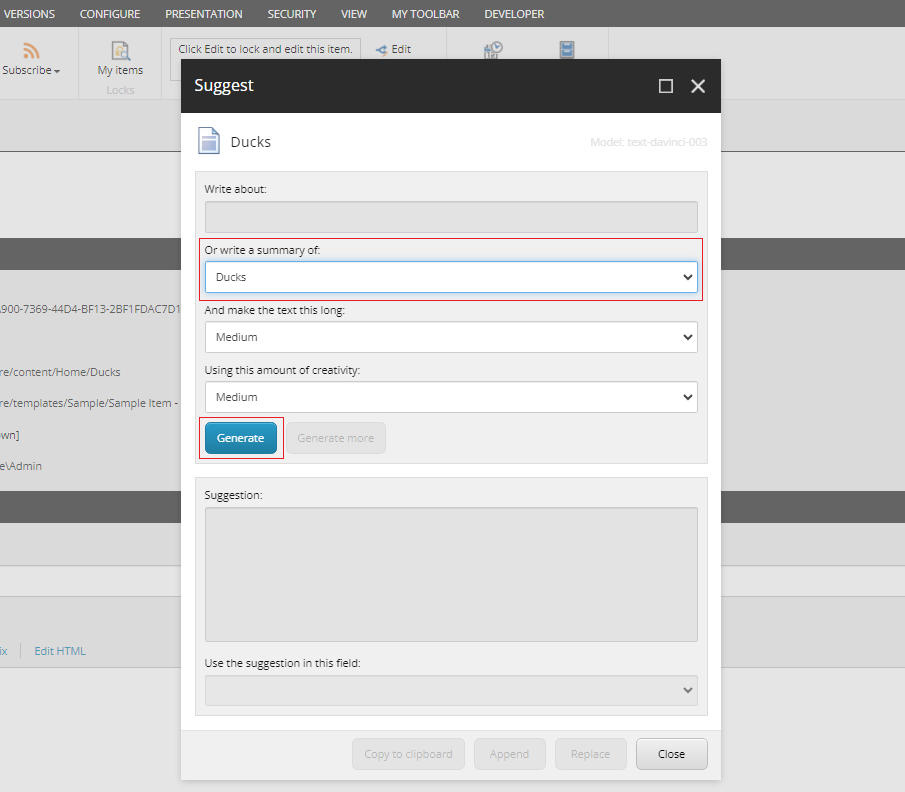
Clicking Generate, Sitecore will now call one of the Open AI models (the text-davinci-003 model in this case), and return an suggestion in the Suggestion text box.
As the Suggestion text box is editable, I can adjust the text and finally insert the suggestion into my Text field:
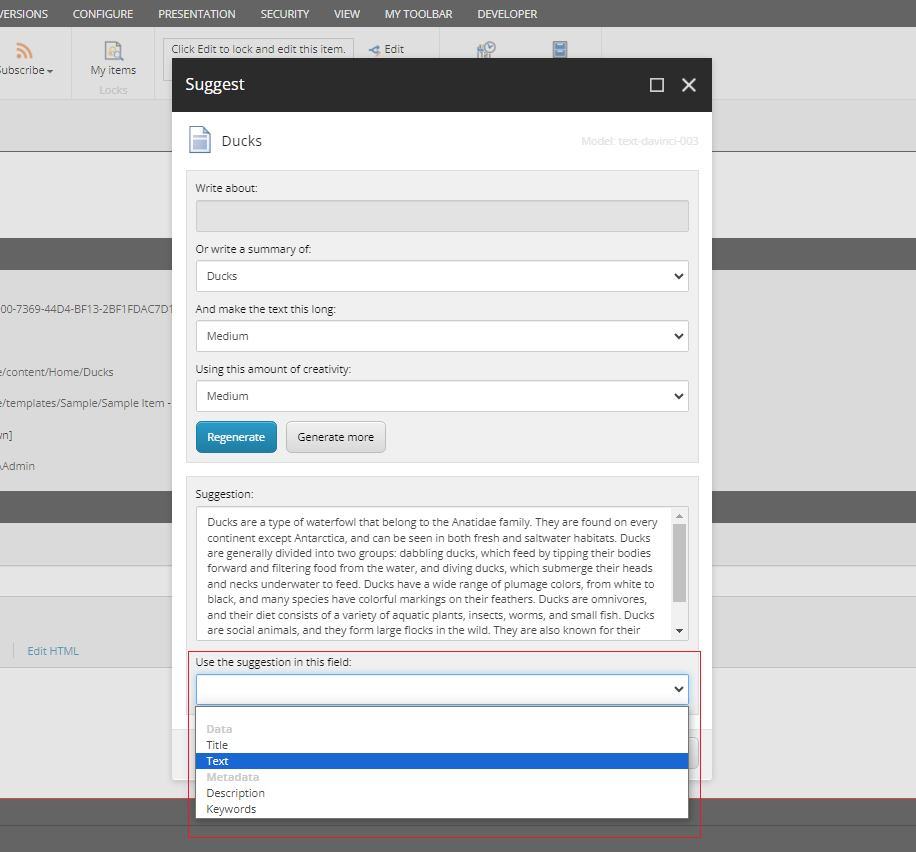
If needed the content editor can regenerate the text or generate additional text. Of cause, instead of generating summaries of existing field values, the editor can also generate texts using a custom prompt:
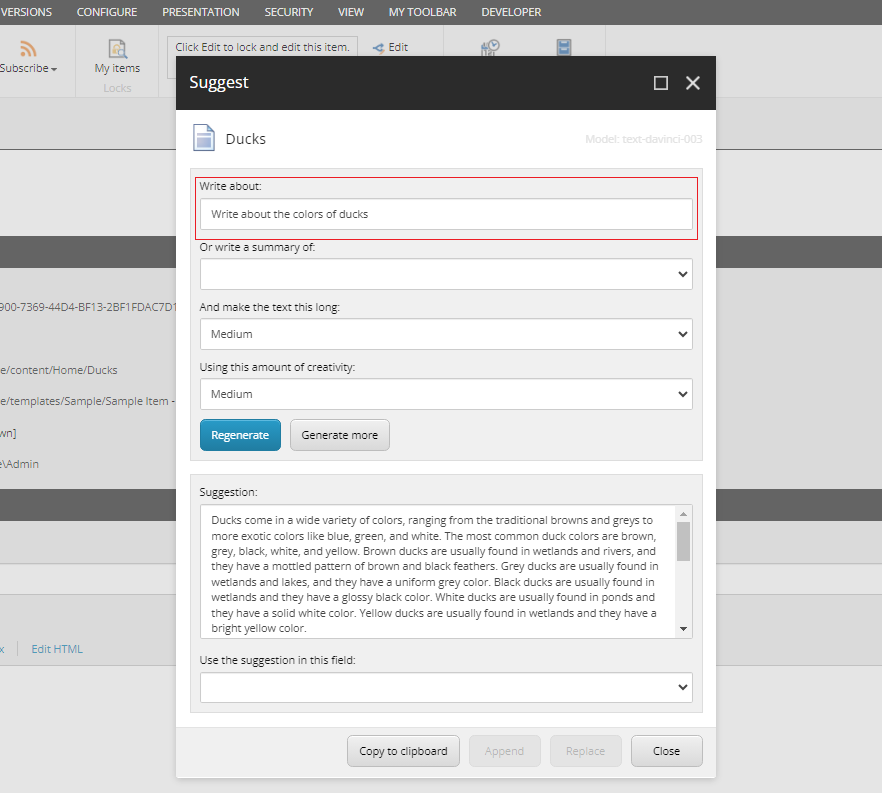
Using the dropdowns, the editor can adjust the length of the text and the “creativity” – also called temperature, which defined the amount of randomness in the text.
Setting up SitecoreSuggest
The README available on my GitHub contains an installation and configuration guide. This includes installing the needed items of configure the Suggest button as well as obtaining a valid API key from Open AI.
The configuration is done in the SitecoreSuggest.config patch file:
<configuration xmlns:role="http://www.sitecore.net/xmlconfig/role/">
<sitecore role:require="ContentManagement or Standalone">
<commands>
<command name="custom:SitecoreSuggest" type="SitecoreSuggest.Commands.SuggestCommand, SitecoreSuggest"/>
</commands>
<settings>
<!--<setting name="SitecoreSuggest.ApiKey" value=""/>-->
<setting name="SitecoreSuggest.BaseUrl" value="https://api.openai.com/v1"/>
<!-- Please make sure to match the endpoint ("completions" or "chat") to the selected model as the model exposed by the endpoints are not the same -->
<setting name="SitecoreSuggest.Endpoint" value="completions"/>
<setting name="SitecoreSuggest.Model" value="text-davinci-003"/>
<setting name="SitecoreSuggest.MaxTokens" value="4097"/>
</settings>
</sitecore>
</configuration>
The config file defines the Open AI API key, base URL, endpoint, model and maximum tokens settings. The API keys of pretty oblivious and the base URL is simply the base URL for the Open AI endpoints, but to understand the other three settings we need to dive a bit into the different endpoint and models.
The Open AI endpoints
SitecoreSuggest integrates with Open AIs API using one of two endpoint: The completions endpoint and the chat endpoint.
The completions endpoint is the easiest to understand: You send a question (also called a prompt or user message) together with the name of the model to use and gets reply (an assistant message). You can configure the endpoint to return multiple choices (multiple assistant messages) and let the user choose the best, but the default behavior is to return the best choice (the one with the highest log probability per token) only. As you can see this endpoint fits the functionality in SitecoreSuggest, and the completion endpoint is used per default.
However, SitecoreSuggest also supports the chat endpoint. The chat endpoint works in much the same way, but instead of sending a single user message, you will send the entire chat-history in an array of messages – both the one you have created (the user messages) and the once you have received from the Open AI model in previous request (the assistant messages). This is called the chat context:
[
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
So, while the chat endpoint is stateless, by allowing a chat history to be send as part of the request, it supports a back and forth conversation – called a multi-turn chat. In the example above you can see that the second question (Where was it played?) only makes sense in light of the complete chat context. It is also possible to put in special system messages to direct the chat in a desired direction.
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
However as SitecoreSuggest handles each new prompt as the start of a new chat to avoid context from a previous suggestion generation to “spill over” into the next it does not utilize the power of the chat endpoint.
The Open AI models
The completions and chat endpoint both expose a range of models – and the same models are not available for both endpoints.
To be honest, the only reason why SitecoreSuggest even supports the chat endpoint is that this endpoint exposes the two most well-known models offered by Open AI: GPT-4 and GPT-3.5-turbo – commonly referred to as ChatGPT. So, if you want to dazzle a client with a ChatGPT integration, these are the models you need, and SitecoreSuggest will not let you down.
However, both models are optimized for multi-turn chats and generate somewhat “chatty” assistant messages. You will probably experience that the completions models – and especially the text-davinci-003 (which is somewhat comparable to GPT-3.5-turbo) – produces the best results.
The list of models is ever changing as new models are created and the knowledge cutoff date is pushed forward (the latest date for the content the model is trained on).
I have tested SitecoreSuggest with the following settings:
| Endpoint | Model | MaxTokens |
| completions | text-davinci-003 | 4097 |
| completions | text-davinci-002 | 4097 |
| completions | text-davinci-001 | 2049 |
| completions | text-curie-001 | 2049 |
| completions | text-babbage-001 | 2049 |
| completions | text-ada-001 | 2049 |
| chat | gpt-4 | (8193) |
| chat | gpt-3.5-turbo | (4097) |
Please note that the MaxToken setting has not effect when using chat endpoint. I have added it to the table for reference, but the setting is actually never used. I will explain why after introducing the concept of tokens.
What is tokens?
When working with both the completions endpoint and chat endpoint we measure the length of text in tokens. A token the building blocks the GPT model uses to analyse texts and is defined by the models tokenizer (which differs from model to model). For the newer models a token is often a word or part of a word, but it may also be a punctuation mark or parenthesis etc. To see how a particular model tokenizes a text, Open AI offers a tokenizer tool:
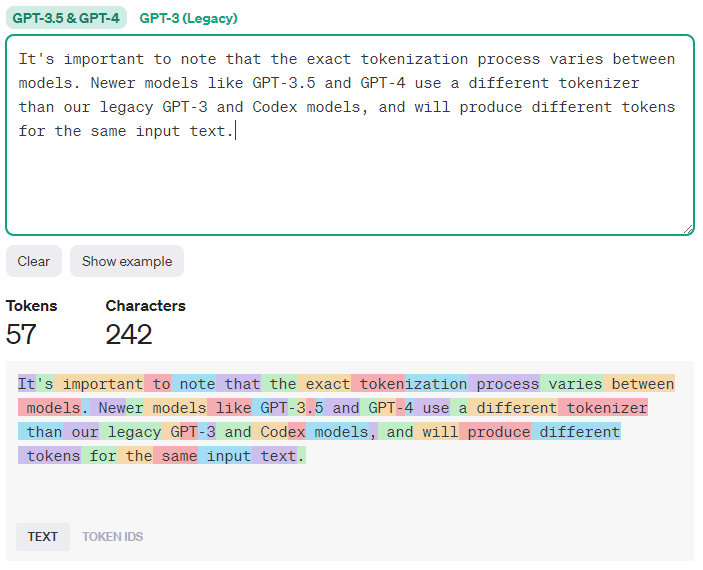
Each model has a maximum limit in terms of tokens. For the chat models these limits apply to the entire chat context (including the current user message and the resulting assistant message) whereas the for the completion models it is simply the current user message and the resulting assistant message as these models do not have a chat context.
This is the reason why both the GPT-4 and the GPT-3.5-turbo chat models comes in a version which support larger chat contexts – potentially generating more context aware responses (GPT-4-32k and GPT-3.5-turbo-16k). For example, GPT-4, supports 8193 tokens for chat context whereas GPT-4-32k supports 32769 tokens.
Both the completions and chat endpoint have a max_tokens property that we can add to the request. However, the default value for the completions endpoint is 16 (which is a really short text), whereas the the default value for the chat endpoint is “infinity”, which basically means “whatever is left” after the number of tokens the the prompt is substracted from the maximum tokens supported by the model.
So for the chat endpoint, SitecoreSuggest will not use the max_tokens property (and the MaxTokens settings can be anything). But for the completions endpoint, we need to send a max_tokens property if we wish to get responses longer that 16 tokens.
The way SitecoreSuggest handles this for the completions endpoint is like this: Without running the tokenizer we really do not know the number of tokens in the user message. But we know it the number of tokens can never be more than the number of characters. So before sending the request to Open AI, the length of the user message will be subtracted from the maximum tokens as defined in the config (e.g. given the prompt Write summary of “Sitecore Experience Platform”. Use around 100 words – which is 71 characters long – the actual maximum tokens sent to Open AI is 4028).
By the way: If you wonder why the maximum token defined as e.g., 4097 (and not 4096) it is because the total tokens of a model is minimum 1 token for the user message and maximum 4096 tokens in the assistant message.
Language support
When sending a prompt to Open AI, SitecoreSuggest does some “prompt engineering” to steer the model in the right direction:
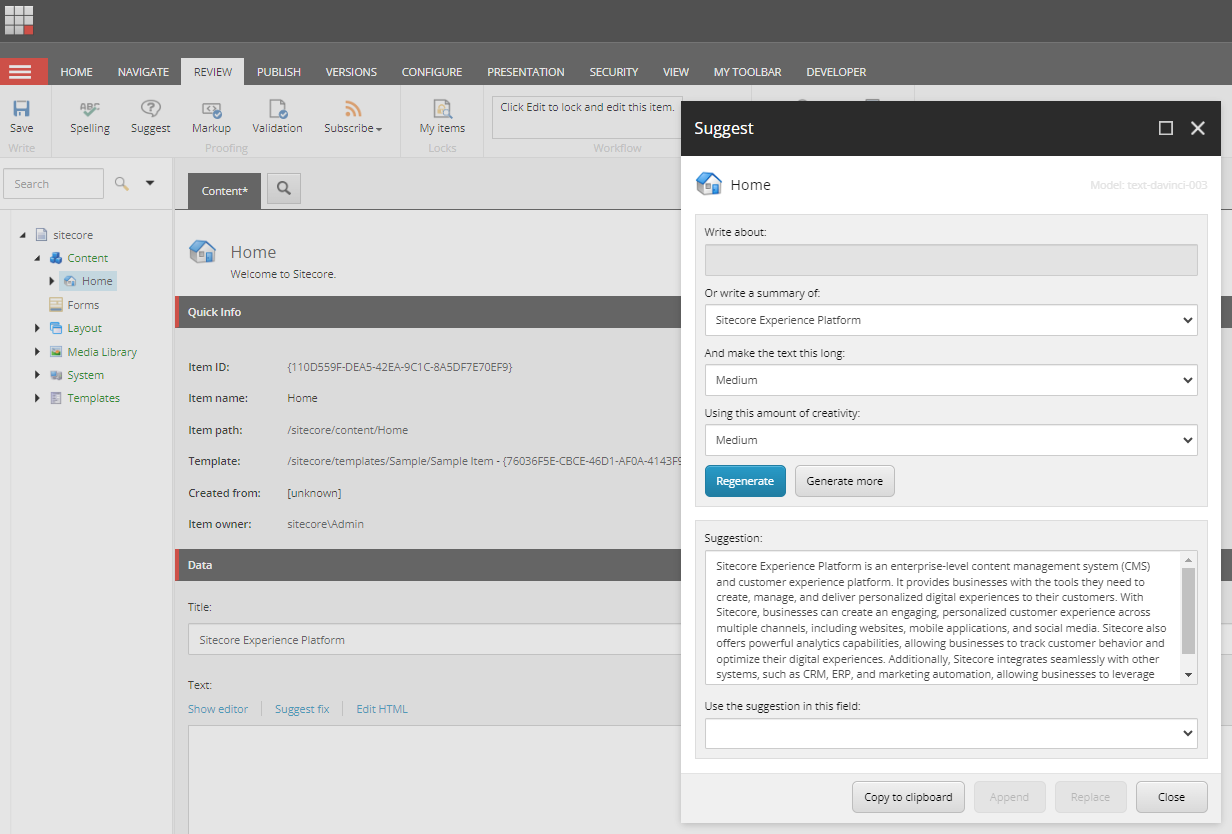
In the screenshot above you can see that I have generated a summary of “Sitecore Experience Platform” (which is the title of the selected item) using a Medium word count. Behind the scenes, this is formatted into the following request:
{
"prompt":"Write summary of \"Sitecore Experience Platform\". Use around 100 words",
"max_tokens":4028,
"n":1,
"stop":null,
"temperature":0.5,
"model":"text-davinci-003"
}
With a chat model such instructions could also be put into the chat context as a system message, but to support the completions models SitecoreSuggest put it into a single prompt.
The language of the prompt directs the GPT model to reply in the same language. This means that if support for other languages is needed, we need to add prompts for generation of summaries and restrict the word count. This is done in the Languages.cs file.
Out of the box SitecoreSuggest supports two languages (en and da). In other languages the Suggest button will be grayed out unless prompts are added for that language in the Languages.cs file.
Advanced settings
Text length
The UI supports three different text lengths:
- Short: 20 words
- Medium: 100 words
- Long: 700 words
If needed this can be adjusted in the file SuggestForm.xml line 44-46. Very long texts might result in a unresponsive UI and might also give problems with the maximum token length depending on the model.
Creativity
The UI supports three levels of creativity – techically called temperature:
- Low: 0.2
- Medium: 0.5
- High: 0.8
Most GPT models support temperatures up to 2, indicating the amount of randomness thrown into the token generation. Temperatures higher that 1 tend to produce text close to gibberish.
If needed the available temperatures can be adjusted in SuggestForm.xml line 54-56.
Summary fields
As we have seen above, SitecoreSuggest allow the content editor to input a custom prompt or to use the value of one of the existing fields of an item to generate summaries.
The use case, as illustrated in the screenshot above is to create a content item, enter a title (e.g. “Sitecore Experience Platform”) and then generate a summary of the title to use in the main text fields of a content item.
The fields available for generating summaries are configured in the Constants.cs file using the SummaryFields array and is per default set to allow summaries from only single-line text fields.
Notice that the summary dropdown will only display the first 70 characters of the field – but the content of the entire field will be used when generating summaries. If no summary fields exist (or they are empty) the summary dropdown is grayed out.
Supported field
When SitecoreSuggest has generated a suggestion, is it possible to either append or insert the suggestion into a field on the selected item.
The fields where appending and inserting are supported are configured in the Constants.cs filed in the SupportedFields array. The default configuration is single-line text, multi-line text and rich text fields. The field types that expect HTML (rich text) also need to be added to the HtmlFields array to allow SitecoreSuggest to format the suggestions using HTML.
Final thoughts
I hope you will find SitecoreSuggest helpful as a starting point for integrating the generative Open AI models into your solution. While the current implementation does not fully utilize the multi-turn chat capabilities for e.g. the GPT-4 and the GPT-3.5-turbo models, it should be pretty easy to extend the implementation.
If you have any suggestions or questions, you are always welcome to reach out – and do not hesitate to using my code (or part of it) in your own solution if you find it useful ☺