
In this post I am going to answer the question “Is a penguin a bird” using Open AIs embedding endpoint. I will touch upon topics from both philosophy and computer science. However, I will try to keep everything practical so that this blog post will be for everyone interested in Open AI and ChatGPT.
Whether a penguin is a bird is, of course, a peculiar question to ask: Most of us can probably agree that a penguin is, in fact, a bird. This is an example of categorization – the act of conceptual differentiation between characteristics of objects, events, or ideas.
Categorization is considered one of the most fundamental human cognitive abilities, hence it is of great interest when creating AIs. Furthermore, while we all have an intuitive understanding of what categorization is, hopefully after reading this post you will understand that it is actually a complex topic.
Human cognition and categorization
The classical view of human categorization is that a category is a set of rules; a list of features, some necessary and some sufficient. Laying eggs is a necessary feature of a bird – but it is not a sufficient feature.
The rule-based approach has an important implication: In the classical view categories are discrete: Either an animal is a bird, or it is not a bird – no birds are “birdier” than other birds.
This idea of categories as “list of rules” goes back to classic philosophers like Aristotle. However, there is evidence that the human brain does not carry out these kinds of logical assertions when categorizing, and that categories are in fact not as discrete as we might think.
Imagine if we ask a child to draw a bird: Most children will not draw a penguin (or an ostrich) but will draw a more stereotypical bird based on their day-to-day experience. I think we all have some intuitive understanding of why: Neither penguins nor ostriches are good “examples” of birds – they are too big, and they cannot fly.
Within cognitive linguistics (the study of cognition and language), there is a theory called the prototype theory. It is basically the idea that when humans categorize birds, we use some mental image for a prototypical bird. For many people, this would be a small bird that can fly, like a sparrow or a blackbird.
We see this in experiments where people are asked to categorize animals : Humans tend to be faster at categorizing typical birds like finches and sparrows than non-typical birds like penguins and ostriches. This indicates that the prototype theory actually tells us something about how the brain works, and that our mental categories might not be as discrete as the classical view of categorization predict.
So, let us instead imagine a whiteboard with post-its on it each containing the name of an animal. If we have a three-dimensional whiteboard (however that would work), having the axes “laying eggs/not laying eggs”, “having feathers/not having feathers” and “can fly/cannot fly”, we would group finches, sparrows together on all three axes forming a group of prototypical birds. But penguins would only be with the prototypical birds on two axes because it cannot fly.
Based on the prototype theory we could say that while a penguin is a bird, it is not a prototypical bird because it is located some distance from the group of prototypical birds.
Overall, a penguin would of cause be closer to our prototypical bird than say some other animal which neither lay eggs, have feathers or can fly, but it is still some distance from our core group of birds. If we had more axes, we could add “big/small”, “can sing/cannot sing”, or “have beaks/not have beaks” to further refine our animal whiteboard.
This might also mean that there is some center on our whiteboard that defines our prototypical bird, but there is not specific species of bird located there. The prototype is simply a mental construct, or an “average bird”.
The embedding space
Now we turn to the world of computers, AI, and natural language processing and see how categorization of words can be done by a computer using word embeddings.
A GPT model typically operates with a “whiteboard” somewhat similar to the one we used to categorize birds. It is called the models embedding space, and it has a lot of axes (1536 for the text-embedding-ada-002 Open AI model I use), so there is no way we can visualize it.
It might be tempting to imagine axes like “size”, “colourfulness”, “ability to fly”, “ability to swim” like we would do in cognitive linguistics. But this is not a correct comparison: In reality the axes are far more abstract and has been calculated during the training of the GPT model. The reason is that there has not been an categorization of animals into “size” or “ability to fly”. Instead, the axes are based on an analysis of the co-occurrence patterns of words in large collections of texts.
Simplifying things a bit, when the GPT model has been trained on massive amounts of text, it has encountered the word “sparrow” and “finch” in the same textual settings. Hence, when processing sentences like “A sparrow is a bird” and “A finch is a bird”, the model has grouped the two words “sparrow” and “finch” together – not because the model understands what a bird is, but simply because the two words tend to be used in the same textual settings.
Notice the shift here: Where we in the classical view on categories and the prototype theory are categorizing based on the human understanding of words, the GPT model is categorizing words without knowing what the words mean.
The link between the “world of meaning” and “world of words” can be expressed in a core idea within natural language processing: “You shall know a word by the company it keeps” (to quote John Rupert Firth). To put it simply, if two words turn up in the same textual contexts again and again, there is a high probability that they share some meaningful characteristics and should be placed together in the embedding space.
There are many different approaches to carrying out such an analysis and construct an embedding space. Some of the recent successes within AI, such as Open AI, are due to the increased computer power available, as well as the improvement of the analytical methods used to process the vast collections of texts available online.
Getting the embedding vector
The cool thing with the Open AI GPT models in particular is that we can actually get the embedding for a particular word. Open AI exposes an endpoint we can call with a text (e.g. a word), and get the corresponding position within the embedding space:
curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"input": “Sparrow",
"model": "text-embedding-ada-002"
}'
If I call this endpoint with the word “Sparrow” I get the following list of coordinates:
"-0,01269785", "0,002324708", "-0,01163808", "-0,01150237", "-0,0191275", "0,016348885", "0,009712401", "-0,02091106", "-0,01668491", "-0,0285879"
– and 1526 more.
This list of coordinations (called the embedding vector) points to a position within the models embedding space.
I can do this with other words like “Finch”, “Dog”, “Cat” and “Penguin” and get similar embedding vectors. The embedding vectors are of course fixed – calling with the same word will produce the same vector.
While we cannot mentally visualize the embedding space nor understand what the axes mean (except that they have some statistical significance) we can certainly calculate the distance between the different coordinates using Pythagoras’ theorem.
To get the distance between two word embeddings, we will simply square the differences on all 1536 axes, add them together and take the square root. Doing this we get the following list of distances between the five words below:
| Cat | Dog | Finch | Sparrow | Penguin | |
| Cat | 0 | 0.4913 | 0.6434 | 0.5984 | 0.5949 |
| Dog | 0.4913 | 0 | 0.6583 | 0.6392 | 0.6408 |
| Finch | 0.6434 | 0.6583 | 0 | 0.5244 | 0.5776 |
| Sparrow | 0.5984 | 0.639 | 0.5244 | 0 | 0.5296 |
| Penguin | 0.5949 | 0.6408 | 0.5776 | 0.5296 | 0 |
As you can see the two words closest together in the embedding space are “Cat” and “Dog”, closely followed by “Finch” and “Sparrow”. This is not surprising as these words probably “keep the same company”, that is turn up in the same textual settings. We see that the word “Penguin” is at a distance of 0.5296 from the word “Sparrow”, 0.5776 from the word “Finch” and 0.5949 from the word “Cat”.
If we want to display the embedding space on a graph we need to reduce the number of axes. I use principal component analysis (PCA) which is an algorithm that reduces the number of axes while maintaining the largest variation.
To understand how that works, let us imagine that we have placed our animals on a three dimensional whiteboard – as post-its in a room, where some of the post-its are floating in the air. We now want to take a picture, and we will try to take it from an angle where the post-its are spread out the most so we can see them all on our two-dimensional image. This is fundamentally what a PCA analysis does to reduce the number of dimensions while keeping the data as intact as possible
By reducing the number of dimensions of the embedding space from 1536 to 2, I am able to create this chart:
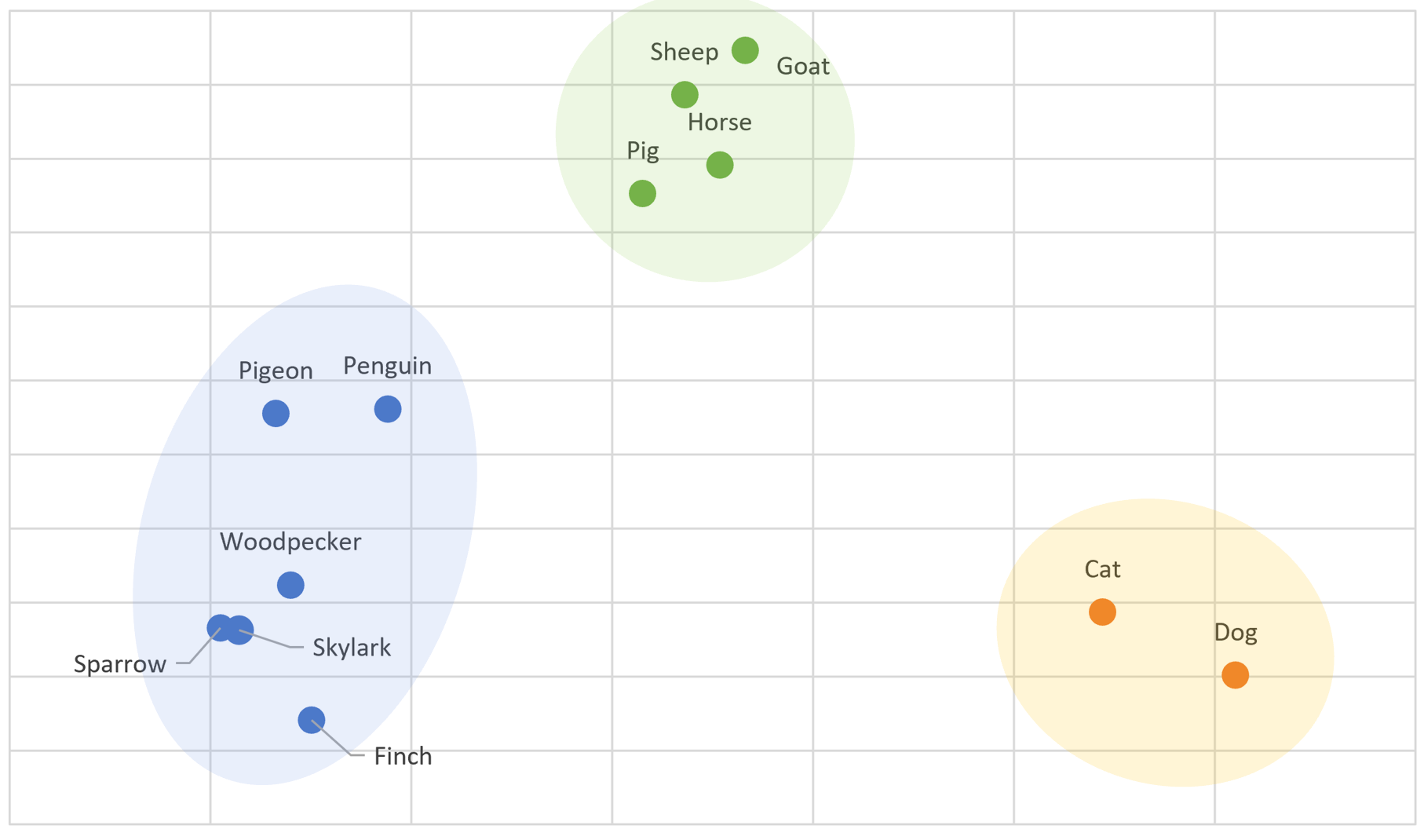
We observe that while the word “penguin” is closest to the group of other bird words, it stands out as an outlier within the embedding space. Interestingly, it is in proximity to a group of words associated with farm animals (highlighted in green).
Final thoughts
In this post we have looked at how humans perform categorization. We have also looked at word embeddings within NLP, how they work and how they are generated during the training of the model.
Of course, within the Open AI GPT models, a lot of work is done during training to refine the process of generating the embedding space, which is not covered in this post. It’s also important to know that the Open AI GPT models do not operate on words but on tokens.
And while this post has been about word embeddings generated during the training of the GPT model, notice that the Open AI GPT models are also able to place complete sentences within the embedding space using a variety of techniques (e.g., contextual embeddings and attention mechanisms). This means that you can get embeddings for a list of sentences and group them using the same techniques as described above.
However, the fascinating aspect of the concept of word embedding is that it allows a relatively non-technical user to get a glimpse of the inner workings of the GPT models, which can often seem like a bit of a black box (at least for me).
Finally, I think it is thought-provoking that the generation of embeddings, based on purely textual analysis without understanding the meaning of each word, produces results that are somewhat similar to human categorization based on actual understanding.