
In this blog post I will show an Azure Pipeline I recently created for performing mutation testing using Stryker. The focus of this post is not so much the mutation tests as the pipeline structure itself. In the pipeline I needed to dynamically create jobs and execute them in parallel using the matrix strategy. So in this post, I will show how this can be achieved.
First let us start with the challenge: My solution contains a number of test-projects – currently around 40. In my Azure Pipeline (defined a YAML file called stryker.yml) I want to take each test-project and perform a mutation test on it using the Stryker tool. If you do not know what mutation tests are, there is a great article on Wikipedia.
However, for this blog post, it is enough to know that a mutation test is a way to “test” tests, and each mutation test takes about 10 minutes to execute. Hence, if I ran my mutation tests one after another, the pipeline would take over to 6 hours to complete for all 40 test projects. This is far too long, and I needed to find a way to speed things up.
Introduction
Before we dive into how I achieved this, let us have a look at my solution. For this post I will use this scaled down version, reducing the number of test-projects:
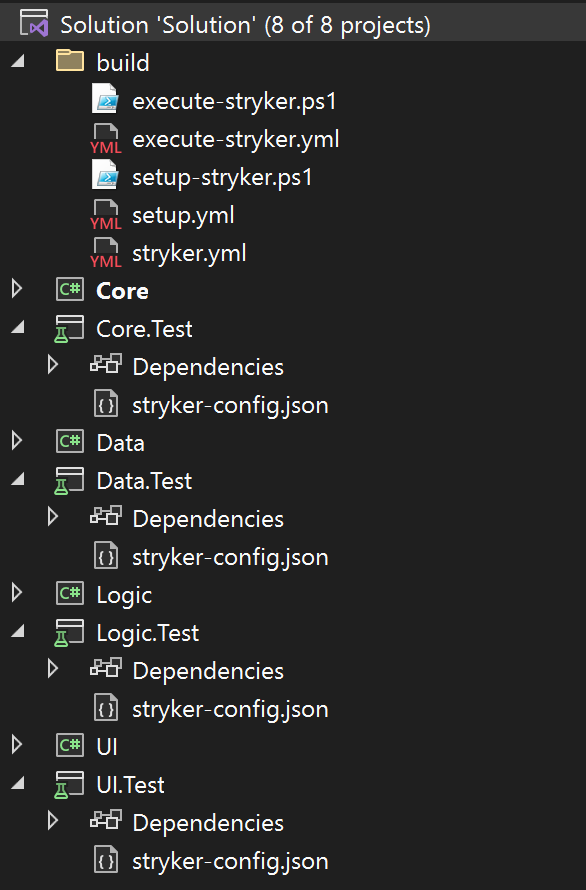
As you can see my scaled down solution contains 4 projects, and 4 matching test-projects. Each test-project contains a styker-config.json, which is the config file I need to pass into the Stryker tool to perform the mutation test on that particular test-project.
In my solution the Stryker config files look like this:
{
"stryker-config": {
"solution": "../Solution.sln",
"project": "Core.csproj",
"report-file-name": "Core"
}
}
Using a matrix to execute jobs in parallel
As each mutation test is an isolated test of a single test-project, the mutation tests can be executed in parallel. Azure Pipelines allow this by using a matrix. The way this is normally done is by setting up a number of matrix entries in the Azure Pipeline and then execute the matrix strategy with a maxParallel.
This strategy will spawn the same job for each matrix entry up to the number of maximum parallel jobs. When one job is done, a new one is created until all matrix entries are processed:
- job: Execute
strategy:
maxParallel: 3
matrix:
Core:
strykerConfig: \Solution\Core.Test\stryker-config.json
Data:
strykerConfig: \Solution\Data.Test\stryker-config.json
Logic:
strykerConfig: \Solution\Logic.Test\stryker-config.json
UI:
strykerConfig: \Solution\UI.Test\stryker-config.json
steps:
- template: build/execute-stryker.yml
parameters:
strykerConfig: $(strykerConfig)
What the matrix strategy does is that it executes the execute-styrker.yml template 4 times, using the 4 strykerConfig parameters provided in the matrix entries. Because the maxParallel parameter is set to 3, only 3 jobs will execute at the same time, but once the first job is done, the next (and in this case 4th job) is started.
The execute-stryker.yml templates looks like this:
parameters:
strykerConfig: ""
steps:
- template: setup.yml
- task: PowerShell@2
displayName: 'Execute Stryker'
inputs:
targetType: filePath
filePath: $(System.DefaultWorkingDirectory)/build/execute-stryker.ps1
arguments: >
-workingDirectory $(System.DefaultWorkingDirectory)
-strykerConfig ${{parameters.strykerConfig}}
Notice the setup.yml template. It points to a template that checks out the solution from Git. As each job in a matrix executes in a separate build agent, this is needed.
The execute-stryker.ps1 script execute the Stryker tool, which is simply a command-line tool that takes the config file as a parameter and produces a HTML report.
dotnet stryker --config-file $strykerConfig--output "${workingDirectory}\Report" --reporter "html"
Dynamically populate the matrix
The problem with this approach is that the Stryker config files are fixed in the pipeline. If a new test-project is added, I would need to update the pipeline to include mutation testing of that new test-project.
Obviously, I would like this to be done dynamically. So, what I did was to create an job before my matrix (called Setup). Within this job I call a PowerShell script (/build/setup_stryker.ps1) in a step called setup_stryker:
- job: Setup
steps:
- template: build/setup.yml
- task: PowerShell@2
displayName: 'Setup Stryker'
name: setup_stryker
inputs:
targetType: filePath
filePath: $(System.DefaultWorkingDirectory)/build/setup-stryker.ps1
arguments: -workingDirectory $(System.DefaultWorkingDirectory)
In this script I locate all Stryker configs in the solution and output the result in an Azure Pipeline variable:
param(
[Parameter(Mandatory=$true)]
[string]$workingDirectory
)
$result = [pscustomobject]@{}
$strykerConfigs = Get-ChildItem
-Path "${workingDirectory}\Solution"
-Recurse
-Include "stryker-config.json"
| Sort-Object
foreach ($stykerConfig in $strykerConfigs)
{
$json = Get-Content -Raw -Path $stykerConfig | ConvertFrom-Json
$project = [io.path]::GetFileNameWithoutExtension($json.'stryker-config'.'project')
if ($null -eq (Get-Member -inputobject $result -name $project -Membertype Properties))
{
$result | Add-Member
-MemberType NoteProperty
-Name $project
-Value @{ stykerConfig = $stykerConfig.FullName.Substring($workingDirectory.Length) }
}
}
$resultJson = $result | ConvertTo-Json -Compress
Write-Host "##vso[task.setvariable variable=strykerConfigs;isOutput=true]$resultJson"
The script will produce this JSON:
{
Core: { strykerConfig: "\\Solution\\Core.Test\\stryker-config.json" }
Data: { strykerConfig: "\\Solution\\Data.Test\\stryker-config.json" }
Logic: { strykerConfig: "\\Solution\\Logic.Test\\stryker-config.json" }
UI: { strykerConfig: "\\Solution\\UI.Test\\stryker-config.json" }
}
The important line in the PowerShell script is the last Write-Host, where I set the Azure Pipeline variable strykerConfigs to the JSON object. This line is recognized by the Azure Pipeline, making the variable available to subsequent jobs.
Now, I can feed the Azure Pipeline variable into my matrix, dynamically populating the matrix entries from the JSON.
The Azure Pipeline variable will be available in the dependencies object (as my job is dependent on Setup), and will be prefixed by the step name (setup_styker):
- job: Execute
dependsOn:
- Setup
strategy:
maxParallel: 3
matrix: $[ dependencies.Setup.outputs['setup_stryker.strykerConfigs'] ]
steps:
- template: build/execute-stryker.yml
parameters:
strykerConfig: $(strykerConfig)
The result
When I run my new pipeline, the Stryker configs are automatically detected and created as matrix entries:
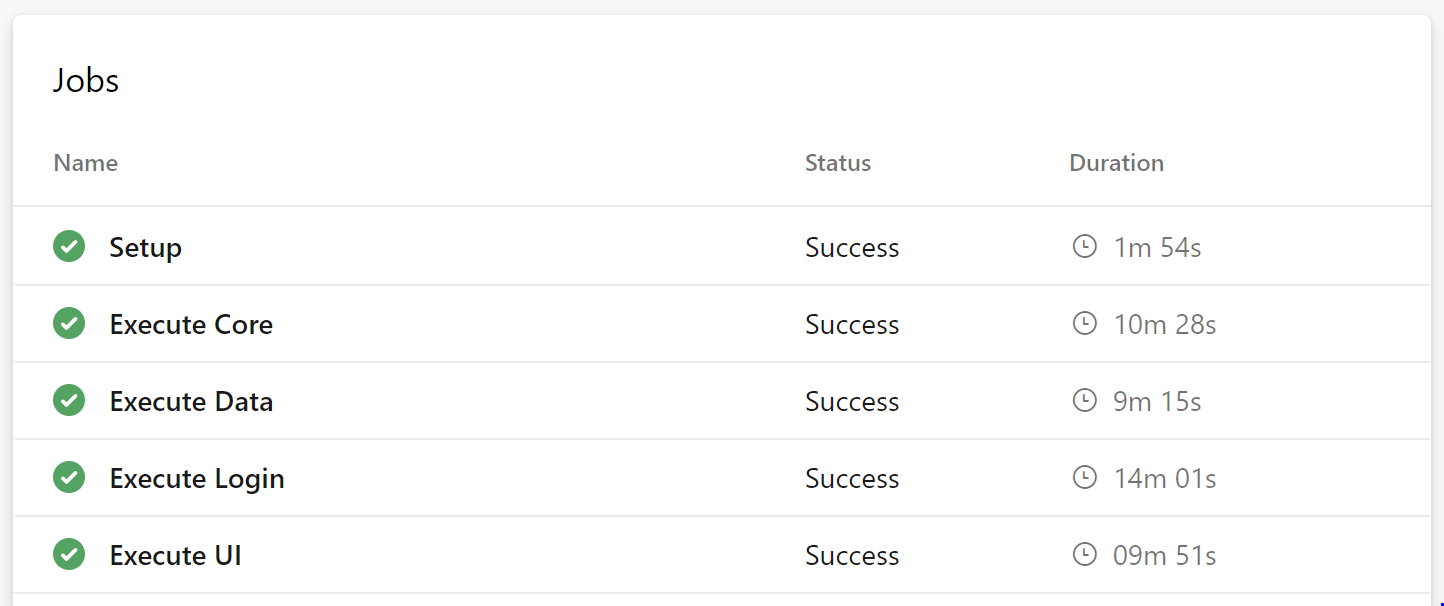
If another test-project is added, containing a stryker-config.json, it will automatically be detected by the Azure Pipeline and added as a new matrix entry. By adjusting the maxParallel parameter, I can determine how many parallel mutation tests I want to perform.
In this case, a subsequent step in the execute-stryker.yml template publishes the generated report:
- task: PublishBuildArtifacts@1
displayName: 'Publish'
inputs:
PathtoPublish: $(System.DefaultWorkingDirectory)/Report
artifactName: Report
This results in a build artifact that contains all the generated reports that can then be further processed.
Summary
Using the matrix strategy, we are able to execute multiple identical jobs in an Azure Pipeline using variables defined in a list of matrix entries.
Most examples you will find online contain a hard-coded list of matrix entries, which makes the number and parameters for each parallel job fixed.
However, by using a JSON object to define the matrix, the matrix entries can be determined dynamically at runtime. In the case described in this post, this approach has been used to process multiple test projects, but of course, this approach can also be used in other scenarios.